
Pandas lesson2: data manipulation provides you the second part of pandas learning tutorial dealing with data manipulations.
Imagine you’re a college student working with a lot of data—maybe it’s information about grades, students, courses, etc. Pandas is like a super handy toolkit that helps you organize and play around with this data in a computer-friendly way.
Data manipulation in pandas refers to the process of altering, transforming, and analyzing data using the Python library called pandas. Pandas is a popular data manipulation and analysis library that provides data structures and functions to effectively manipulate and process structured data, primarily in tabular form, similar to spreadsheets or databases. It’s widely used in data analysis and data science tasks.
Here are some common data manipulation tasks you can perform using pandas
1. Loading Data: You can use pandas to easily read data from files (like Excel sheets) and put them into neat tables called DataFrames. Think of these like supercharged spreadsheets.
2. Filtering and Selection : Want to see only the data that matches certain conditions? Pandas lets you do that. For instance, you can quickly find students who scored above a certain grade.
3. Data Cleanup : If your data is messy (missing values, weird formats), pandas has tools to clean it up so that it’s easier to work with. You wouldn’t want strange gaps or mistakes in your data, right?
4. Calculations : Let’s say you want to find the average grade in a course or the total number of students who took a particular class. Pandas helps you do math on your data without breaking a sweat.
5. Grouping : If you want to see how things are going across different classes or semesters, pandas can group your data and give you summaries. For example, you can see the average grades per course.
6. Sorting and Ranking : If you’re curious about who got the highest grades, you can sort your data by grades. And if you want to see who’s doing really well, you can give ranks based on their scores.
7. Combining Data : Imagine you have one list of students and another with course info. Pandas can help you put these together so you can see who’s taking what class.
8. Making Sense of Data : If you want to visualize your data as graphs or charts, pandas can team up with other tools to help you make cool visuals.
9. Playing with Data : You can do all sorts of things with pandas, like transforming your data into different shapes, trying out different ideas, and seeing what makes sense.
Basically, pandas is like a friendly data butler for you. It takes your messy, confusing data and helps you turn it into useful information that you can understand and work with.
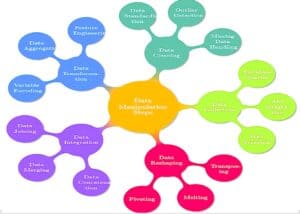
Data manipulation in connections with different terms is shown in the schematic diagram below.
The python code block is embedded here in the below section. please scroll through the jupyter notebook embedded page to see the complete content and practice it in google colab notebook.
After completing these exercises, the next lesson to study is : file-read-and-write-operations
1 thought on “Pandas lesson2: Data Manipulation for datascience”